用户画像是什么
用户画像是根据用户的社会属性及各类行为,抽象出一个标签化的用户模型。其核心工作主要包括两点:
构建标签集: 根据实际业务需求、平台、数据等,确定用户画像的标签集合。如针对不同需求,可能需要用户兴趣画像、年龄性别画像、人群画像、地址画像、生命周期画像等,每类用户画像都可以确定对应的标签集合。
为用户贴上标签: 根据用户的社会属性和各类行为数据,利用机器学习模型或者相关规则,为用户贴上对应的标签。
用户画像的作用
通过构建用户画像,可以帮助我们更好地了解用户和产品,在个性化推荐和排序、用户精细化运营、产品分析,及辅助决策等方面,发挥很大的作用。如图1所示。
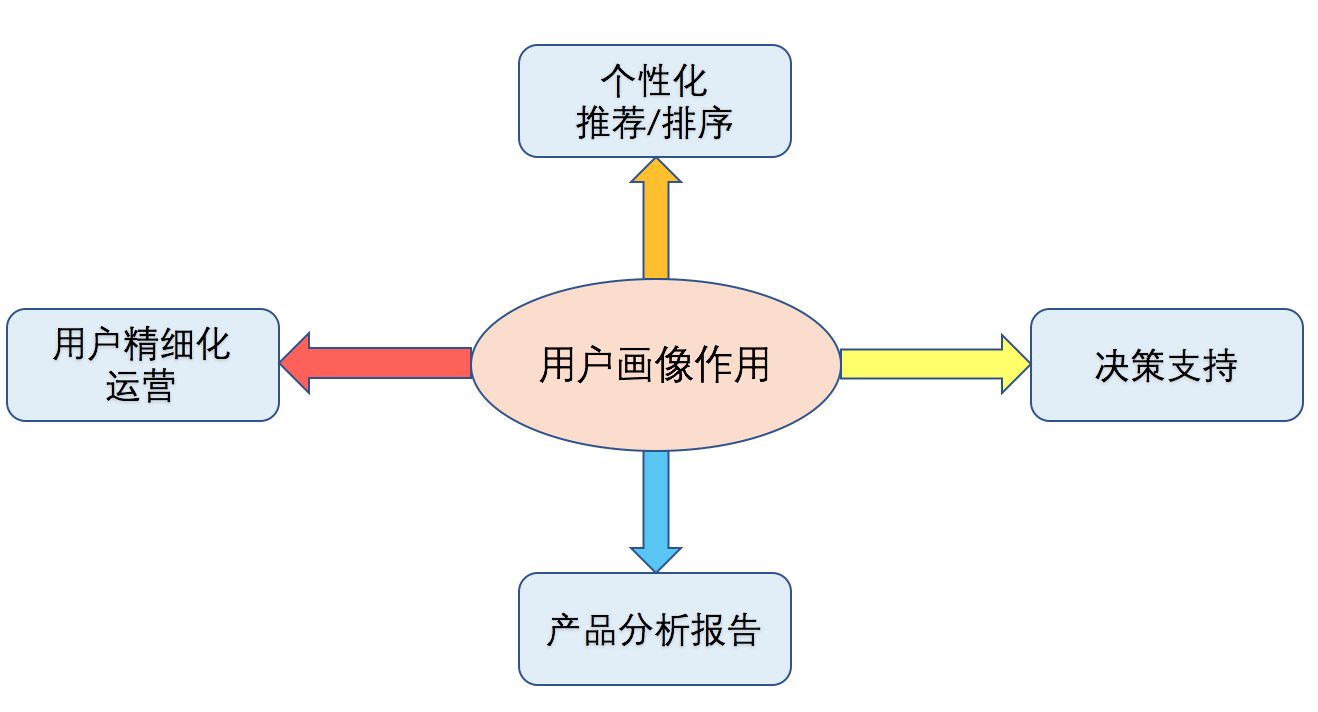
个性化推荐和排序
个性化推荐:通过构建用户兴趣画像,可直接用于基于内容的推荐算法中,在一定程度上解决推荐过程中的冷启动问题;另外,用户画像可用于候选召回模块,在推荐排序阶段可作为有效的特征进行使用。
搜索排序:通过加入用户画像特征,能够产生更加个性化的搜索效果,提升用户体验。用户精细化运营
通过用户画像,使得在用户运营时,只选择相关的用户进行运营,提升运营的效率,节省运营成本。如通过用户流失预测模型,得到预流失用户,可以只针对这部分用户采取挽回措施;在进行相关运营推送活动中,只针对目标用户进行推送,可以减少不必要的资源浪费和用户干扰。产品分析报告
通过构建用户画像,有助于对产品分析,如产品人群分布,产品趋势预测等,产出相关的产品分析报告。决策支持
通过构建用户画像,能够更加了解平台用户相关信息,有助于产品决策。其它
另外,用户画像还可用于定向广告投放,垂直行业分析等。
用户画像建模
在用户画像建模时,要建立哪些维度用户画像,往往和实际的业务需求相关。如为了在推荐中解决item冷启动问题,需要建立用户内容兴趣画像、内容风格画像;为了个性化运营,需要建立人群画像、地域画像、年龄性别画像等;为挽回可能流失用户,需要建立用户生命周期画像等。
兴趣画像
不同的时间段,用户兴趣会有变化,针对该特点,在建立用户画像时,可以考虑建立三类兴趣画像:长期兴趣、短期兴趣和即时兴趣。其中长期兴趣是指比较长的时间内(如一年),用户表现出的持续的稳定的兴趣;短期兴趣是指用户最近一段时间内(如一个月),用户表现出的兴趣;即时兴趣是指用户当前上下文环境中(如单次会话或单次浏览),用户表现出的临时兴趣。
本文我们主要针对用户长期兴趣进行建模。对于短期兴趣,可以对相关的行为权重根据时间进行衰减;对于即时兴趣,可以对当前上下文中用户的交互行为进行建模。
用户兴趣画像(长期兴趣)建立的流程如图2所示:
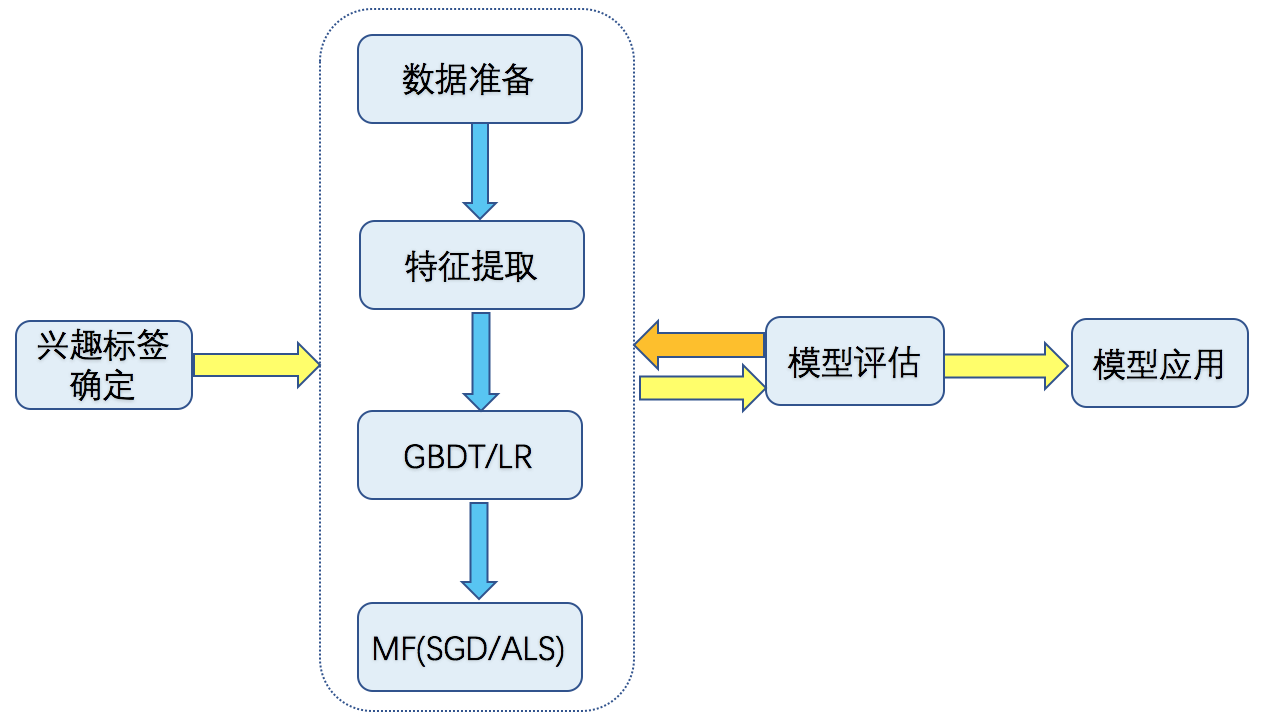
兴趣标签确定
兴趣标签建立,要根据具体的业务需求,平台特点等进行构建。如对于电商平台,用户的兴趣更多的是指用户日常喜欢买的产品类别;对于资讯类平台,用户兴趣画像更多的是指资讯所属的类别、标签等;对于ins, in等图片社交平台,用户兴趣画像更多的是指图片内容或场景信息。具体而言,兴趣标签由两部分组成:兴趣类目和详细标签。对于兴趣类目,通过借鉴相关平台的分类信息(如新浪,优酷,pinterest等),结合自身平台特点,由专业人员制定。对于详细标签,可通过爬虫、nlp等相关技术,并依靠一定的人工审核进行确定。
用户兴趣挖掘
数据准备:主要包括基础行为日志、用户基础属性信息、item基础属性信息等。对于每个数据源,做数据清洗、数据规范化等,形成方便使用的中间数据。
特征提取和样本构建:根据准备好的中间数据,通过用户属性信息、item属性信息、行为日志构建正负样本。提取的特征可以为:基于user维度的特征、基于label维度的特征、基于user和label的组合特征。
user维度特征:user对应的曝光、点击、点赞、评论、发表、收藏、关注、搜索等相关特征
label维度特征:item对应的曝光、点击、点赞、评论、发表、收藏、label类别特征、搜索等特征
user和label组合特征:user对应label的曝光、点击、点赞、评论、发表、收藏、搜索等特征。
对于构建的正负样本,划分为训练集、验证集和测试集。模型训练和预测:对上述步骤生成的正负样本,训练GBDT/LR模型。在互网产品中,很多情况下,由于负样本比例明显高于正样本,如点击行为小于曝光,购买行为小于曝光等。此时,需要对负样本进行采样后,再训练相关模型。在模型预测时,只保留预测得分大于一定阀值的用户兴趣。
兴趣协同扩展:仅通过模型预测阶段,存在一个潜在的问题,当用户对一个标签没发生过任何行为,或者行为次数很少时,该兴趣很可能永远不会被预测出来。一种比较好的方式是采用协同过滤,利用矩阵分解模型,得到用户和兴趣的隐语义向量,并根据在用户和兴趣在隐语义空间的内积计算用户对每个兴趣的得分。关于矩阵分解模型一般可采SGD和ALS算法进行求解,可参考[1]。
用户兴趣评估
指标评估:在验证集上对准确率和召回率进行评估,并通过特征优化、模型优化不断提升验证集上的准召率。对于验证集上表现最好的特征和模型,作为最终的用户画像模型,并在测试集上评估效果。
用户调研:对于预测出的用户画像结果,采用用户调研的方式进行评估。- 用户兴趣画像应用
用户兴趣画像预测和评估通过后,可进一步用于个性化推荐、推送、个性化搜索排序等相关应用中。
年龄性别画像
年龄性别画像和兴趣画像构建过程比较类似,不同之处在于:年龄性别标签容易构建;年龄性别画像不需要通过矩阵分解进行标签扩展。
标签确定
性别标签:男、女分别对应一个标签。
年龄标签:根据业务需求,确定需要划分的年龄段,每个年龄段对应一个年龄标签。年龄性别挖掘
年龄性别画像可以像兴趣画像那样,通过GBDT/LR模型进行预测。也可以采用其它方法,如[2]采用朴素贝叶斯相关方法进行挖掘,并通过在隐语义空间寻找k近邻,根据其邻居信息来平滑标签挖掘结果。年龄性别挖掘评估
年龄性别的评估和兴趣挖掘评估类似。但是,由于平台上用户的年龄和性别分布有时候很不均衡,对所有年龄段的用户进行评估会使得整体的评估结果受主体年龄段用户的影响很大,因此,我们采用对每个年龄段单独评估准确率,召回率和F值,再求所有类别的均值。对于性别的评估类似,对每个性别的用户单独评估,然后再求两个性别的评估均值。年龄性别挖掘应用
年龄性别挖掘好之后,可用于推荐、排序、定向广告、个性化用户运营等。
地域画像
地域画像主要根据用户与地址相关的信息进行构建,相对兴趣、年龄性别画像,地域画像不需要比较复杂的模型,往往通过规则就可以得到比较合理的结果。此处我们以常住地用户画像挖掘为例进行说明。
标签确定
可以直接使用省份、城市、区、县等名称作为地域标签。地域画像挖掘
用户常住地相关的特征有:访问app时的gps地址,访问app时的ip对应的地址,手机号码归属地,用户注册时填写地址等,可以根据每个特征计算用户对应地址的得分,然后对各个来源的计算结果进行加权,最后根据加权结果确定用户常住地信息。用户对应某个特征的地址得分:
根据特征$s$计算的用户$u$对于地址$i$的得分如式1所示:
$score_{u,s,i} = \sum \lambda_t \; p_{u,s,t,i}\;\; (式1)$
其中,$p_{u,s,t,i}$表示用户$u$在距离当前日期的第$t$天,对应特征$s$和地址$i$访问app的次数, $\lambda_t$为时间衰减系数,可以按照如下式2和式3进行计算。
$\lambda_t= \begin{cases}
1-t/T\, & t\leq T\\
0, & t>T
\end{cases}
\;\;(式2)$
$\lambda_t=\lambda_0 \alpha^t\;\;(式3)$
其中$\alpha$为0到1之间的数值。容和各特征s对应地址得分:
$score_{u,i}=\sum score_{u,s,i}\;w_s\;attr_i$
其中$w_s$是根据特征重要性设定的权重,$attr_i$是属性$i$对应的权重,如可以根据地址是否够详细,设置相对应的的权重。地址越详细,权重越高。确定用户常住地
对于所有地址得分从高到低排序,得到列表$L$。然后从高到低开始,如果连续两个地址得分相差不大,则将当前地址加入常住地集合$S$,继续向后遍历列表;否则停止遍历。此时列列表$S$中所有地址为用户的所有常住地。
地域画像评估
地域信息的挖掘结果,来自和标签强相关的特征统计,准确率比较高。在评估时,可以将某一项特征的统计结果作为标签,衡量根据其它特征挖掘得到的结果的准确率和召回率。地域画像应用
用户地域画像可用于精细化用户运营,定向广告等相关场景。
生命周期画像
用户生命周期画像,对于公司了解产品趋势,分析产品对用户的粘性具有重要作用。同时,可针对不同生命周期的用户采用不同的运营方案,提升运营效果,减少对用户的干扰。如针对初期用户进行功能的教育引导,对流失用户进行唤醒等。另外我们还可以针对非流失用户,建立流失预测模型,进行流失预警。
生命周期划分
由于app功能、用户使用频次、使用需求等不同,其对应生命周期划分也不完全一致。可采用如下方法来划分用户的生命周期:
得到留存用户
根据所有用户注册后,$N$天后是否还在使用app,得到$N$天后的留存用户集合S。一般$N$可以根据app性质设定,原则是$N$天后用户还在使用app,证明该用户已经习惯使用该app。留存用户使用频次趋势统计
对留存用户,统计从注册后到稳定使用app之间,平均每个时间周期$T$的登录频次。综合所有用户情况,得到每个时间周期$T$的平均使用频次。其中时间周期$T$根据app性质进行设定。标签确定及划分标注
根据每个时间周期$T$的登录频次变化趋势,确定生命周期的标签及划分标准。- 标签确定
我们根据登录趋势变化,确定生命周期标准。如图3所示(虚拟数据),在第一个到第二个周期$T$用户登录频次变化非常明明显,从第二个到第八个周期用户登录频次变化相对较小,从第八后周期之后用户登录频次几本趋于稳定。基于此,我们可以确定划分标准为初级用户、成长期用户、稳定期用户和流失用户。其中初期用户对应登录频次较高,成长期用户对应登录频次逐渐降低,稳定期用户是登录频次趋于稳定,流失用户是$N$天后不再登录app的用户。
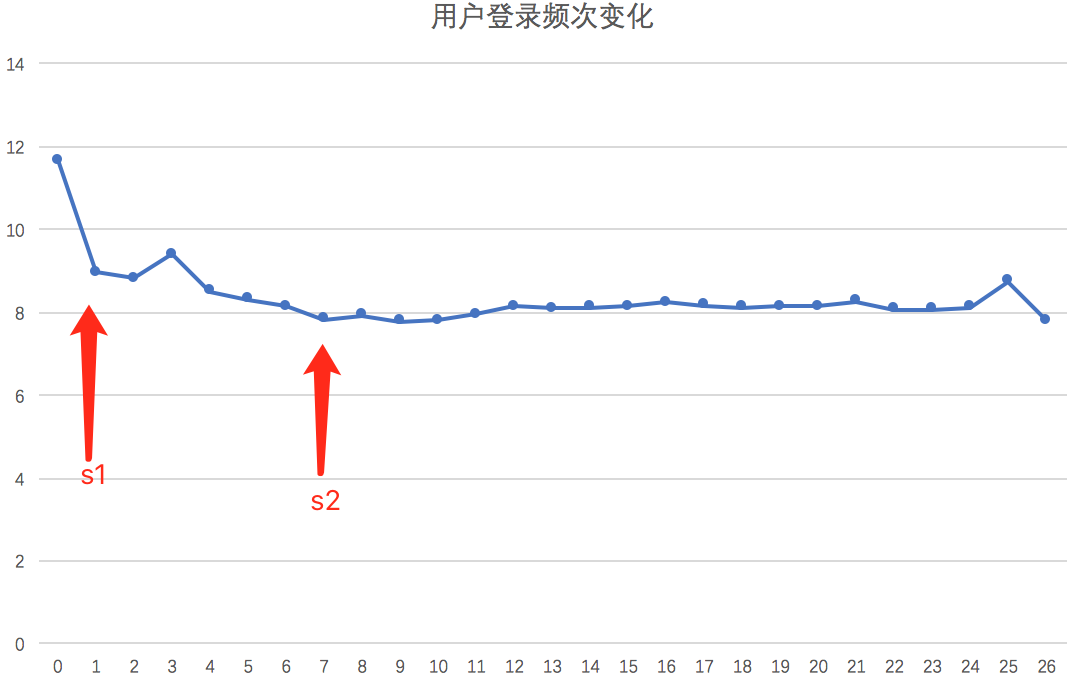
图3 用户登录频次变化 - 划分标准
对于流失用户,明确为为$N$天后不再登录的用户。对于其它三个标签划分,一种比较直观的划分是:根据图3的两个箭头s1和s2作为分界点,s1划分初级用户和成长期用户,s2划分成长期用户和稳定期用户。但是由于不同用户使用频率存在有较大差别,会导致划分不合理的情况。如有的用户可能只使用过很少的次数就进入成熟期。因此,我们可以使用的方法是:将对应周期结束时的登录总次数作为划分标准。我们假定$f$表示用户当前使用app次数,具体划分标准如下所示:
初期用户: $f \lt 12$
成长期用户: $12\leq f \leq 63$, 63为前7个周期$T$的总登录次数。
稳定期用户: $f \gt 63$
- 标签确定
流失预测
用户的各个生命周期之间存在转换关系,如图5所示:初期用户、成长期用户、稳定期用户。如果$N$天未登录,会变成流失用户。流失用户重新登录,则变为初期用户。此处,我们认为如果用户$N$天未来,对于app有些新功能没有使用过,需要引导教育。因此,该类用户被划分为初期用户。
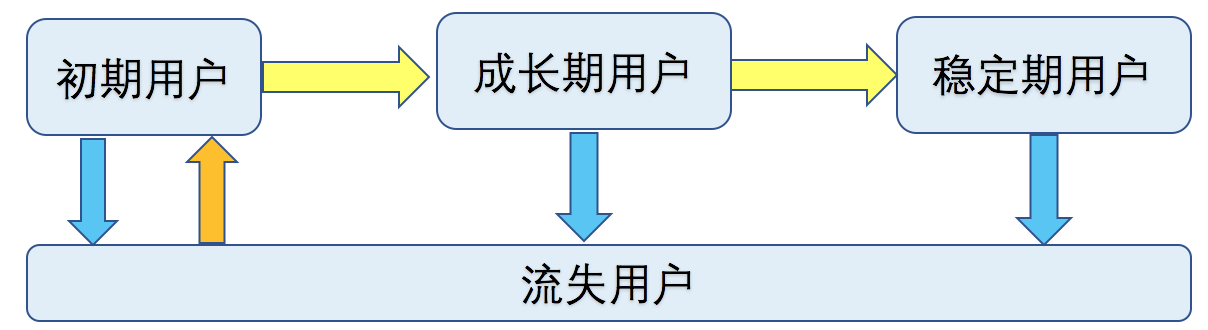
用户流失预测模型和兴趣画像构建类似,不同之处在于:标签易确定;不需要矩阵分解进行标签扩展;需要采用较多的时间序列相关特征。
标签确定
对于用户流失预测模型,主要包括2个标签:预警用户和正常用户模型训练和预测
模型的训练和预测和兴趣画像基本类似,主要是使用的特征不同、不需要进行标签扩展。- 特征提取
用户使用app频率、频率的变化趋势、使用功能等,都和用户是否将要流失有很大的关系。我们可以提取用户每个周期的登录频次、间隔的1-N个周期登录频次差值、每个周期使用的各个功能模块的频次、间隔1-N个周期各个功能模块使用频次的差值等,作为流失预测模型的特征。 - 模型训练和预测
用户在平台上注册的时间不同,如有的用户注册只有不到一周,有的用户可能超过几年。针对这种情况,可以针对注册时间不同的用户,划分为多个类别,同一个类别的用户注册日期相近。这样,对于注册时间距离当前时间较近(如不到1周)的用户,可以采用其所有时间段的行为进行训练和预测。对于注册时间距离当前时间较长(如超过2个月)的用户,可以采用最近一段时间(如最近2个月)的行为进行训练和预测。
- 特征提取
模型评估
对于训练好的模型,在测试集上评估模型的准确率、召回率和F值- 模型应用
针对处于未流失用户,通过流失预测模型,可以有效地找出即将流失的用户,从而进行用户预警,通过相关运营手段防止其变为流失用户。
其它画像
除了上述画像之外,还可以从很多的维度去描述用户,并为之建立画像。如人群画像、功能偏好画像等,p图相关画像(如贴纸风格画像、滤镜画像等)。针对社交网络,可以有消费兴趣画像、生产兴趣画像等。各类画像的挖掘方法很多,本文描述了自己学习过程中使用的一些方法,希望能对大家有用。
参考资料
[1] iamhere1, “矩阵分解模型的分布式求解”, 2018.01, https://iamhere1.github.io/2018/01/03/mf/
[2] Hu J, Zeng H J, Li H, et al. “Demographic prediction based on user’s browsing behavior”, International Conference on World Wide Web, 2007.05, pp.151-160.