YouTube采用的推荐系统,是当前工业界最大最复杂的推荐系统之一,服务于上十亿的用户,目的是从不断增加的的海量的视频集合中,为每个用户推荐个性化的内容。
YouTube的个性化推荐系统主要存在三方面的挑战:
数据规模: 由于YouTube庞大的数据规模,很多在小数据集上非常有效的推荐算法无法使用,需要更加特殊的分布式学习算法和在线推荐服务系统。
新颖度: 每一秒都有很多的视频上传到YouTube, 推荐系统需要及时考虑这些新上传的视频以及用户在视频上的新操作等,这就需要从 exploration/exploitation的角度去权衡。
数据特点和噪声: 由于用户行为的稀疏性以及一些不确定的额外因素干扰,通过用户的历史行为进行推荐是非常困难的;在YouTube上很少能获得用户的显示喜欢的内容,因此只能根据隐式反馈信号进行建模;视频内容的元数据不够结构化;推荐算法的设计需要对所有这些数据特点都是鲁棒的。
为了保持和google内其他产品的一致,YouTube内部正在做的一件事情是将深度学习作为一种通用的解决方案,用于解决几乎所有的机器学习问题。该论文成果建立在google brain开源的tensorflow之上。tensorflow提供了可以大规模训练各种网络结构的实验框架,本篇论文实验使用了几千亿的样本,训练十亿的参数。
系统概述
如图1[1]所示,整个系统包括两个深度神经网络, 一个用于生成候选集,另一个用于排序。
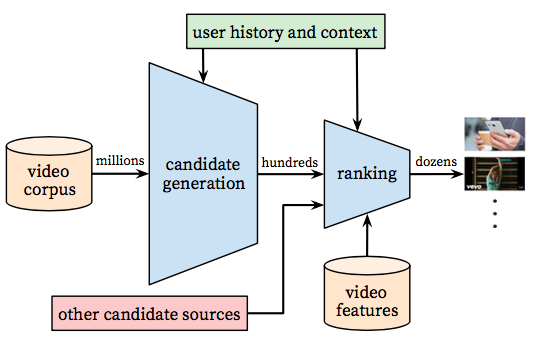
图1:推荐系统结构:包括触发和排序2个模块,触发模块用于从海量的数据中生成较少的候选集,排序模块对触发结果做更精细的选择
触发模块通过输入用户的历史行为,从全量的集合里面,检索出视一个较小的子集(几百个),该模块通过协同过滤的方式,提供了相对弱一些的的个性化。用户之间的相似性通过观看的视频id, 搜索query的分词结果,以及用户的人口属性信息等来衡量。
排序模块针对触发结果列表,做更加精细的筛选。排序模块采用更加丰富的特征用于描述用户和视频,通过使用特定目标函数训练得到的模型,对视频进行打分。最后得分最高的一些视频推荐给当前的用户。
通过结合触发和排序两个模块,具有两个明显的优势:(1)可以使得从很大的候选集合内,以较小的时间成本推荐个性化的内容给用户(2)可以融合多个算法的结果进行排序(具体使用时,可以将每个算法的结果合并,然后利用排序模块进行打分,取最高得分的视频推荐给用户,较好地实现多推荐算法融合)。
触发模块
在触发阶段,会将海量的视频集合进行初步过滤,剩余几百个用户最可能喜欢的视频。
用分类的思想对推荐建模
我们把推荐问题建模为一个分类问题,预测在当前时刻$t$, 给定用户$u$和上下文$c$, 预测要观看的video的类别(有多少个候选video, 就有多少个类别)。如下式所示:
$P(w_t=i|U,C)=\frac{e^{v_i\,u}}{\sum_{j\in V} \; e^{v_j\,u}}\;\;(式1)$
其中$u$表示的用户和上下文的隐语义向量,$v_j$表示第$j$个候选video的隐语义向量。隐语义向量的获取实际上是把一些稀疏的实体信息(如user, video等)映射为N维空间的稠密实向量,而DNN的作用就是从用户的浏览历史和上下文中学习隐语义向量$u$, $u$进一步可用于在$softmax$分类器中预测对应的video类别(即当前用户在上下文环境C时,最可能看的video).
尽管YouTube上存在显式反馈数据,但是论文中依然使用隐反馈数据,当用户看完一个视频则认为是正样本。这是由于用户的显示反馈行为是非常稀疏的,无法较好地进行模型的训练和预测,而用户存在大量的隐反馈行为,通过采用隐反馈数据,可以有效地以完成模型的训练和预测。
高效的多类别训练:为了有效地完成数十亿类别的模型训练,论文采用了一种负采样的方法,首选根据负样本的分布采样负样本,然后通过重要性加权进行纠正,具体使用的方法可以参见文献【2】。对于每个样本,其真实的标签和负采样的类别标识都通过最小化交叉熵优化模型。实际上,每次都采样几千个样本,相对于传统的softmax, 其训练速度提升100倍以上。另外一种可行的高效训练方法是$hierarchical softmax$,但由于遍历每个节点等于在将无关的类别进行分类,这使得分类更加复杂,有损模型的效果。
在线服务阶段,需要在几十毫秒内计算当前用户最可能喜欢的$N$个video, 这需要一个近似的得分方案,使得时间延迟对于类别数量的增长是低于线性的。论文的采用的是基于hash的方法【3】,从点积空间寻找最近的$N$个类别作为推荐的结果。
模型架构
对于每个video, 学习其在固定词典上的高维嵌入向量,并把这些向量作为神经网络的输入。每个用户的观看历史可用一个变长的video id序列来表示,每个video id可以通过嵌入的方式得到一个稠密的向量。这些向量通过聚合操作,得到单个向量(实验表示通过对所有向量求平均是最好的策略),作为神经网络的输入。这些video的嵌入向量,和其他的模型参数,都通过误差反向传播,并利用梯度下降方法进行学习。图2是触发模块的模型架构,其输入同时包括观看的video特征和和其他各种非video特征。
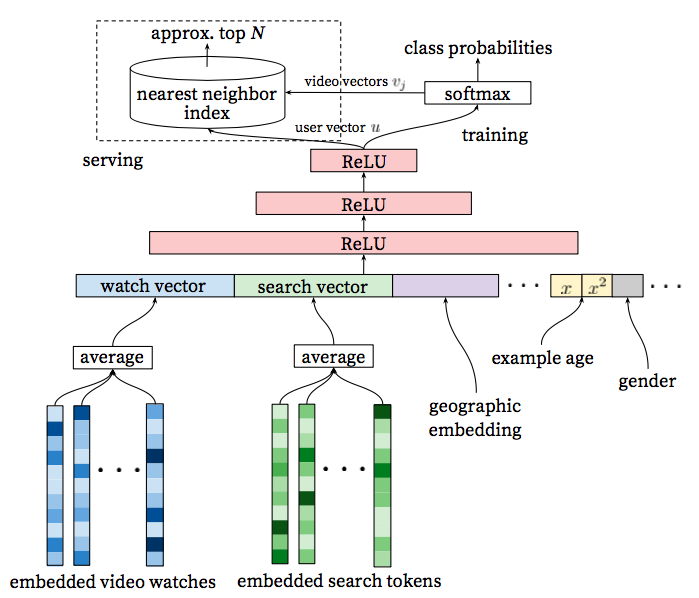
图2:触发模块结构图:嵌入的稀疏特征和和非稠密特征同时作为模型的输入,同一个用户的多个嵌入特征通过平均的方式,得到固定的尺寸,并输入到隐藏层,所有的隐藏层都是全连接。在模型训练阶段,通过最小化交叉熵,并采用梯度下降的方法对sampled softmax进行求解。在serving阶段,通过一个近似最近邻的查找,得到数百个候选推荐结果
特征多样性
使用DNN作为矩阵分解方法的进一步泛化,可以带来的一个非常明显的优势:任何的连续特征和离散特征,都能比较容易地加入到模型中。
搜索历史:和观看历史非常近似,每个搜索query都可以分词为unigrams和bigrams,每个分词可以嵌入为向量,将用户的所有token对应的嵌入向量进行平均,形成代表用户搜索历史的特征。
人口属性:人口属性提供了非常重要的先验信息,有助于对新用户进行合理的推荐。地域和设备信息都通过嵌入的方式,拼接到整个模型的输入中。比较简单的离散或连续特征如用户性别、用户登录状态、用户年龄等,直接以归一化到0-1之间的实数形式输入到神经网络。
样本年龄: 经过持续的观察得知,用户更加喜欢新内容,尽管不会以牺牲相关性为代价。如果我们简单地推荐新内容给用户,可能会使得推荐的内容不够相关。使用机器学习的方式进行推荐时,由于模型的训练,都来在历史样本,会使得历史的内容更容易得到推荐。论文的推荐系统产生的推荐结果,在训练窗口的几个星期内的流行度变化显示了用户在每个时间的平均喜好程度,同时表明video的流行度不是固定不变的,而是符合多项式分布的。为了去除不同时间因素的影响,我们把样本年龄特征加入模型进行训练,在server阶段,该特征置为零,表示当前时间在训练窗口的末尾。图3显示了该方法的效果:
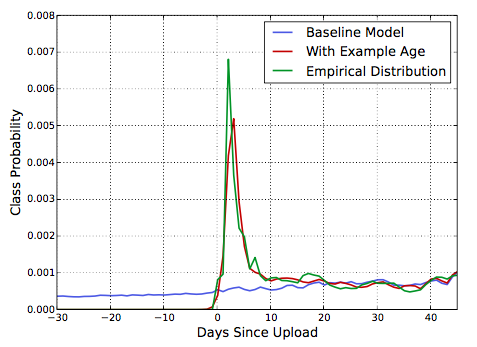
图3:加入样本年龄特征后模型效果,使用样本年龄作为特征后,模型可以精确表示video的上传时间和独立于时间的属性。没有这个特征,模型预测的是整个训练时间窗口的平均喜好程度
标签和上下文选择
通过解决一个问题,然后将这个计算结果转换到特定的上下文环境中使用,是推荐业务经常使用的一种方式,这种方式对于线上的AB测试非常重要,但是离线实验对于在线的效果不是很好评估。
训练样本来自所有用户观看记录,而不只是推荐结果的观看记录。否则,很难推荐出新的video, 而只是在旧的内容进行exploitation;通过确保每个用户具有相同样本数,可以避免部分活跃用户的行为带来的训练误差,提升模型的在线效果;为了防止模型在原始问题上过拟合,对于分类器信息的使用需要非常谨慎。例如用户刚搜了一个query, 分类器在进行推荐时会选择搜索结果页中对应的视频,但是推荐用户刚搜过视频对于用户的体验是不好的,通过将原始的query分词后,抛弃序列信息,以bag of words的方式提供特征,分类器会不受原始搜索结果的影响
用户观看视频的顺序会对最终的观看概率有较大影响。因此,在训练的时候,用历史发生的行为+历史行为之后的视频观看结果作为样本进行训练,要好于用所有的行为+随机的视频观看结果进行训练。如图4所示:
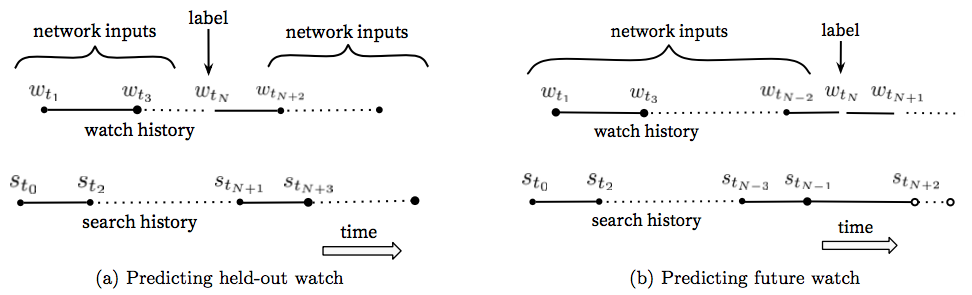
图4:lable和输入上下文。 选择样本标签及对应的上下文对于样本准备更有挑战,但是对于在线的效果提升非常有帮助,4-b的效果要远远好于4-a.在4-b中,$t_{max}$表示训练窗口的最大观察时刻,$t_{max}-t_N$表示样本年龄特征
特征与DNN层数实验
通过增加特征和DNN的层数,可以显著提升模型的效果,如图5所示。1M数量的video和搜索token嵌入分别嵌入到256维的向量,每个用户观看历史为最近的50个video和最近的50个query分词结果,softmax层输出1M个video的多项式分布概率。模型的结构是塔型,最底层的单元数最多,每向上一层单元数都减少一半。0层的网络等价于一个线性分解器,和YouTube早先的推荐系统类似。在进行网络调优时,网络的宽度和层数逐渐增加,直到带来的收益不再增加或者收敛变得困难。
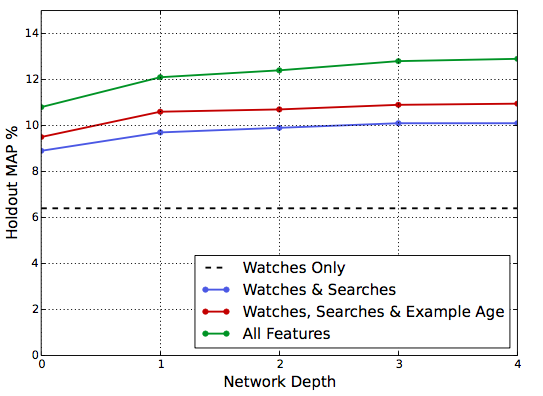
图5:模型效果与特征、DNN层数的关系。 Mean Average Precision (MAP) 随着特征、层数的增加而提升
排序模块
在排序阶段,由于只对几百个候选样本进行打分,可以采用更多特征描述video, user和video的关系。排序不仅可以上述rank模型的结果进行精选,也可用于对多个来源的候选结果进行融合。论文采用和触发模块类似的模型结构,并利用LR模型对候选结果进行打分和排序,并返回得分最高的video作为排序模块的结果输出。排序模型最终以平均每次曝光的观看时间作为优化目标,而非点击率,通过点击率作为优化目标容易推荐带有欺骗性的视屏,这些视频虽然容易吸引用户点击,但用户点进去后会很快离开。排序模型的架构如图6所示:
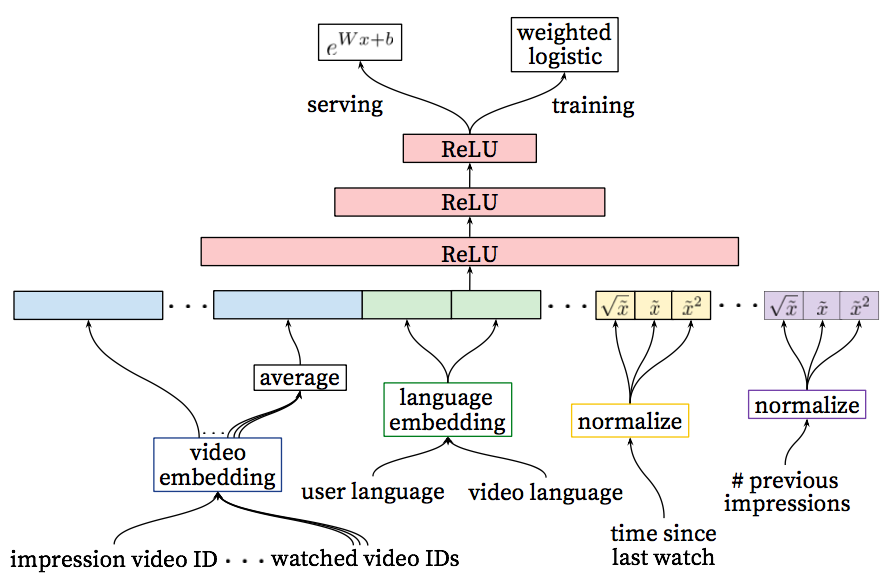
图6:深度排序模型架构,输入包括univalent(如当前待评分的video id)和multivalent(如用户最近浏览过的多个video id)的离散特征的嵌入、连续特征的各个幂运算等,共输入几百个特征
特征表示
排序模块包括离散特征(单值特征和多值特征)和连续特征,其中离散特征包括二值特征(如是否登录状态)和多个值的离散特征(如video id), 多个离散值的特征包括univalent(如当前待评分的video id)和multivalent(如用户最近浏览过的多个video id),论文也使用了其他特征,如是否描述item(如曝光),是否描述user/context(如query)
Feature Engineering
尽管深度神经网络可以减少工程的难度,但是大多数特征还是不能直接输入到神经网络,需要花费一定的时间将用户、video等特征转化为可以直接输入的形式。
最有用的特征是描述用户之前和item或者类似item的交互特征,如用户从对应的频道看的视频个数、用户最近看该主题video的时间,这类特征具有很强的泛化性能,候选集分数,候选集来源,历史的video曝光情况等非常重要。
Embedding Categorical Features
同触发模块类似,将稀疏的离散特征嵌入到稠密的表示空间,用于神经网络的输入。每个独有的ID序列都会被映射到这样的一个空间,映射后特征的维度同ID值个数的对数成正比。在训练之前,通过一些扫描所有的ID建立查找表,在后续的训练过程中可以直接查找和更新这个表。对于ID值非常多的空间,根据点击的频率进行从高到低进行排序,对TOP N的ID进行嵌入,其他ID嵌入结果直接由0向量表示。multivalent离散特征的嵌入结果是多个univalent嵌入结果的均值。
在同样的ID空间的不同特征,都共享该特征的嵌入结果。如曝光的video ID,上次观看的video ID等。不同的特征虽然共享嵌入的结果,但是分别输入到神经网络进行训练,可以在学习时利用到每个特征表示的具体信息。嵌入结果的共享对于模型提升泛化性能、训练速度,减少内存消耗都是非常重要的。
Normalizing Continuous Features
通常神经网络对于特征的尺度和分布非常敏感,而基于树的组合方法对尺度和分布不敏感。因此对于论文模型,为连续特征选择合适的规范化方法非常重要。为了使得原始特征映射到0-1之间的均匀分布,采用公式2进行特征的转换,该转换类似于在训练之前,为特征值的分位数进行差值。
$\bar x = \int_{-\infty}^xd\,f\;\;(式2)$
除了规范化后的$\bar x$, 同时增加$\bar x^2$和$\sqrt{\bar x}$,同时捕获原始特征的超线性和次线性,赋予模型更加丰富的表达能力,实验证明通过这些特征的加入,可以提升模型的效果。
期望浏览时间建模
论文的目标是对期望浏览时间进行建模,其中正样本是有点击行为的样本,负样本是没有发生点击行为的样本。每个正样本都有对应的浏览时间,负样本的浏览时间为0. 为了预测期望浏览时间,采用加权逻辑回归的方法,正样本的权重是对应的浏览时间,负样本使用单位权重,采用交叉熵作为目标函数。这样模型学习的优势比odds为$\frac{\sum T_i}{N-k}$, 关于优势比的定义可参见【3】。其中$N$是训练样本数,$k$是正样本数,$T_i$对应第i个视频的浏览时间。由于实际正样本的数量比较少,优势比等价于$E[T](1+P)$, $P$是点击率,$E[T]$是期望浏览时间,由于$P$比较小,该目标进一步可以近似为平均观看时间。在预测阶段,使用指数函数$e^x$作为激活函数得到优势比odds, 作为预测的平均浏览时间的近似值。
针对隐藏层的实验
表1是不同隐藏层配置对应的对于next-day的预测结果,评估指标是用户加权平均损失,每个配置都是评估同一个页面的正负样本,如果正样本分数低于负样本,那么正样本的浏览时间是预测错误浏览时长, 用户加权平均损失定义为所有预测错误的浏览时间占比所有评估对的浏览时间之和
结果显示,增加神经网络的层数和每一层的宽度,都可以提升模型的效果。在CPU预算允许的前提下,论文采用了1024 ReLU =》 512 ReLU =》 256 ReLU的配置。不使用连续特征的幂特征,损失增加0.2%。正负样本权值设置相等,损失增加非常明显,达到4.1%。

表1:不同ReLU单元隐藏层配置对next-day的预测结果影响,评估指标是用户加权平均损失
总结
论文描述了YouTube视频推荐的深度网络结构,主要分为触发模块和排序模块
触发模块:论文采用的深度协同过滤,能够使用各种信号特征,并通过多层网络建模信号之间的交互,效果好于之前的矩阵分解模型;通过建模时考虑不对称的行为序列,能够更好地使用所有信息对未来进行预测,使得离线训练的模型能更好地用于在线预测;对于分类器的所有信号特征不直接使用,而是对其中一些特征经过仔细分析和加工后使用,能够获得更好的推荐效果;使用样本的年龄特征,能够避开时间因素的干扰,使得预测结果独立于时间特征。
排序模块:模型在预测平均观看时间方面,好于之前的线性方法、组合树的方法。通过使用标签之前的用户行为,用户的效果有较大的提升;深度网络需要对离散特征做嵌入处理,对连续特征做规范化处理;多层网络能够有效地建模数百个特征之间的非线性交互;采用加权逻辑回归的方式,对于正负样本分别赋予不同全值,使得我们能够较好地学习优势比,并用优势比来预测浏览时间。在使用用户平均加权损失来评估效果时,该方法的效果要远远好于直接用点击率进行建模。
参考文献
【1】P Covington, J Adams, E Sargin. Deep Neural Networks for YouTube Recommendations, Acm Conference on Recommender Systems, 2016 :191-198
【2】S. Jean, K. Cho, R. Memisevic, and Y. Bengio. On using very large target vocabulary for neural machine translation. CoRR, abs/1412.2007, 2014.
【3】T. Liu, A. W. Moore, A. Gray, and K. Yang. An
investigation of practical approximate nearest
neighbor algorithms. pages 825–832. MIT Press, 2004.
【4】nside_Zhang, http://blog.csdn.net/lanchunhui/article/details/51037264, 2016